5 High-Impact Reverse App Applications for Industrial 3D Modeling
In industries like automotive, manufacturing, and engineering, creating accurate 3D models of components — especially
")
In industries like automotive, manufacturing, and engineering, creating accurate 3D models of components — especially

In the age of digital transformation, one technology stands out as a true game-changer: computer
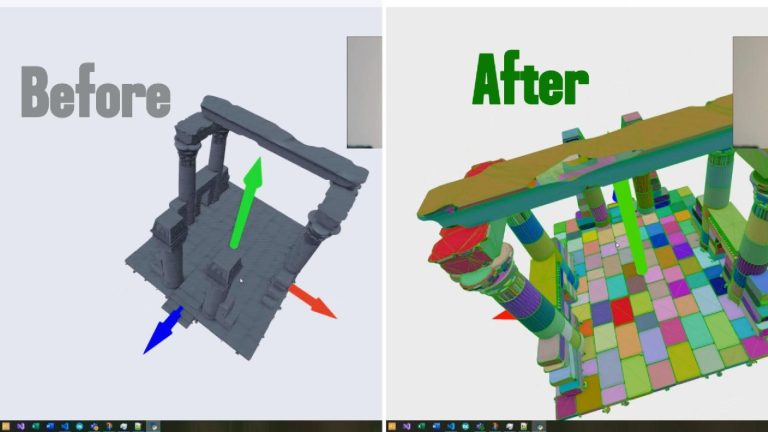
In industries like automotive, manufacturing, and engineering, precise 3D models are not a luxury —

Marking products with unique IDs has become standard across industries. These identifiers unlock opportunities for

Visual classification is a simple and self-explanatory process, at least for humans. Machines, on the other hand, have a much tougher time classifying objects in the images. Hence, classification has become one of the most engaging challenges for computer vision engineers.

Managing research and development projects is often non-linear and unpredictable. Traditional project management tools like

Increasing the speed of a production line often requires updating existing vision systems to maintain

It is possible to take many different project management courses online or offline, but all of them, when it comes to the topic of research and development will only glance at or ignore it completely.

Background estimation is a common problem in image processing that, in some cases, could be resolved by using a simple method. If you imagine a highway with cars passing by, most of the time, the background is visible (e.g., road, trees, traffic signs) with an occasional “disturbance” in the form of a vehicle. These outliers are usually easily solved by using a median filter.

Main reason why there are so many topics related/dedicated to lights and cameras on our page is because I believe programming should always be the last resort for solving a problem. Choosing a correct light or camera could save countless hours of coding or even save a project. Coding is fun but wasting time on low quality images is often just that – wasting time. This article is written from a computer vision perspective, but it can be applied to a bigger picture.

Overexposure is the effect when optical sensor reaches saturation and from that point on, only the maximum pixel value (usually 255) is shown. Overexposed objects can cause a lot of headaches in image processing, but there are ways in which it can be made useful.

Extension methods are a great way of advancing an existing library without modifying the original class. But it is possible to do something even more powerful with it. Even the dlls of a closed source commercial library can be extended. Halcon is a commercial computer vision library which will be used for showcasing this application.